Upgrading to Destinations V2
What is Destinations V2?
Airbyte Destinations V2 provides you with:
- One-to-one table mapping: Data in one stream will always be mapped to one table in your data warehouse. No more sub-tables.
- Improved error handling with
_airbyte_meta: Airbyte will now populate typing errors in the_airbyte_metacolumn instead of failing your sync. You can query these results to audit misformatted or unexpected data. - Internal Airbyte tables in the
airbyte_internalschema: Airbyte will now generate all raw tables in theairbyte_internalschema. We no longer clutter your destination schema with raw data tables. - Incremental delivery for large syncs: Data will be incrementally delivered to your final tables. No more waiting hours to see the first rows in your destination table.
To see more details and examples on the contents of the Destinations V2 release, see this guide. The remainder of this page will walk you through upgrading connectors from legacy normalization to Destinations V2.
Destinations V2 were in preview for Snowflake and BigQuery during August 2023, and launched on August 29th, 2023. Other destinations will be transitioned to Destinations V2 in early 2024.
Deprecating Legacy Normalization
The upgrade to Destinations V2 is handled by moving your connections to use updated versions of Airbyte destinations. Existing normalization options, both Raw data (JSON) and Normalized tabular data, will be unsupported starting the upgrade deadline.
As a Cloud user, existing connections using legacy normalization will be paused on the upgrade deadline. As an Open Source user, you may choose to upgrade at your convenience. However, destination connector versions prior to Destinations V2 will no longer be supported starting the upgrade deadline.
Note that Destinations V2 also removes the option to only replicate raw data. The vast majority of Airbyte users prefer typed final tables, and our future feature development will rely on this implementation. Learn more below.
Breakdown of Breaking Changes
The following table details the delivered data modified by Destinations V2:
| Current Normalization Setting | Source Type | Impacted Data (Breaking Changes) |
|---|---|---|
| Raw JSON | All | _airbyte metadata columns, raw table location |
| Normalized tabular data | API Source | Unnested tables, _airbyte metadata columns, SCD tables |
| Normalized tabular data | Tabular Source (database, file, etc.) | _airbyte metadata columns, SCD tables |
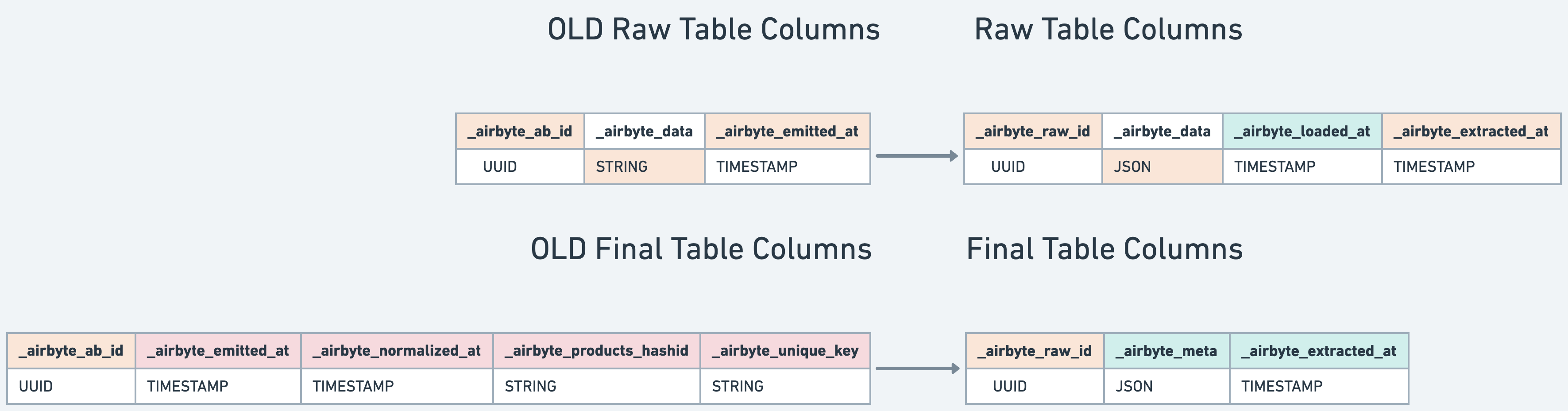
Whenever possible, we've taken this opportunity to use the best data type for storing JSON for your querying convenience. For example, destination-bigquery now loads JSON blobs as type JSON in BigQuery (introduced last year), instead of type string.
Quick Start to Upgrading
The quickest path to upgrading is to click upgrade on any out-of-date connection in the UI. The advanced options later in this document will allow you to test out the upgrade in more detail if you choose.
[Airbyte Open Source Only] You should upgrade to 0.50.24+ of the Airbyte Platform before updating to Destinations V2. Failure to do so may cause upgraded connections to fail.
- The upgrading process entails hydrating the v2 format raw table by querying the v1 raw table through a standard query, such as "INSERT INTO v2_raw_table SELECT * FROM v1_raw_table." The duration of this process can vary significantly based on the data size and may encounter failures contingent on the Destination's capacity to execute the query. In some cases, creating a new Airbyte connection, rather than migrating your existing connection, may be faster. Note that in these cases, all data will be re-imported.
- Following the successful migration of v1 raw tables to v2, the v1 raw tables will be dropped. However, it is essential to note that if there are any derived objects (materialized views) or referential constraints (foreign keys) linked to the old raw table, this operation may encounter failure, resulting in an unsuccessful upgrade or broken derived objects (like materialized views etc).
If any of the above concerns are applicable to your existing setup, we recommend Upgrading Connections One by One with Dual-Writing for a more controlled upgrade process
After upgrading the out-of-date destination to a Destinations V2 compatible version, the following will occur at the next sync for each connection sending data to the updated destination:
- Existing raw tables replicated to this destination will be copied to a new
airbyte_internalschema. - The new raw tables will be updated to the new Destinations V2 format.
- The new raw tables will be updated with any new data since the last sync, like normal.
- The new raw tables will be typed and de-duplicated according to the Destinations V2 format.
- Once typing and de-duplication has completed successfully, your previous final table will be replaced with the updated data.
Due to the amount of operations to be completed, the first sync after upgrading to Destination V2 will be longer than normal. Once your first sync has completed successfully, you may need to make changes to downstream models (dbt, sql, etc.) transforming data. See this walkthrough of top changes to expect for more details.
Pre-existing raw tables, SCD tables and "unnested" tables will always be left untouched. You can delete these at your convenience, but these tables will no longer be kept up-to-date by Airbyte syncs. Each destination version is managed separately, so if you have multiple destinations, they all need to be upgraded one by one.
Versions are tied to the destination. When you update the destination, all connections tied to that destination will be sending data in the Destinations V2 format. For upgrade paths that will minimize disruption to existing dashboards, see:
- Upgrading Connections One by One with Dual-Writing
- Testing Destinations V2 on a Single Connection
- Upgrading Connections One by One Using CDC
- Upgrading as a User of Raw Tables
- Rolling back to Legacy Normalization
Advanced Upgrade Paths
Upgrading Connections One by One with Dual-Writing
Dual writing is a method employed during upgrades where new incoming data is written simultaneously to both the old and new systems, facilitating a smooth transition between versions. We recommend this approach for connections where you are especially worried about breaking changes or downtime in downstream systems.
Steps to Follow for All Sync Modes
- [Open Source] Update the default destination version for your workspace to a Destinations V2 compatible version. This sets the default version for any newly created destination. All existing syncs will remain on their current version.

- Create and configure a new destination connecting to the same database as your existing destination except for
Default Schema, which you should update to a new value to avoid collisions.
- Create a new connection leveraging your existing source and the newly created destination. Match the settings of your pre-existing connection.
- If the streams you are looking to replicate are in full refresh mode, enabling the connection will now provide a parallel copy of the data in the updated format for testing. If any of the streams in the connection are in an incremental sync mode, follow the steps below before enabling the connection.
Additional Steps for Incremental Sync Modes
These steps allow you to dual-write for connections incrementally syncing data without re-syncing historical data you've already replicated:
- Copy the raw data you've already replicated to the new schema being used by your newly created connection. You need to do this for every stream in the connection with an incremental sync mode. Sample SQL you can run in your data warehouse:
- BigQuery
- Snowflake
- Redshift
- Postgres
Enter your stream's name and namespace to see the SQL output.
If your stream has no namespace, take the default value from the destination connector's settings.
Enter your stream's name and namespace to see the SQL output.
If your stream has no namespace, take the default value from the destination connector's settings.
Enter your stream's name and namespace to see the SQL output.
If your stream has no namespace, take the default value from the destination connector's settings.
Enter your stream's name and namespace to see the SQL output.
If your stream has no namespace, take the default value from the destination connector's settings.
- Navigate to the existing connection you are duplicating, and navigate to the
Settingstab. Open theAdvancedsettings to see the connection state (which manages incremental syncs). Copy the state to your clipboard.
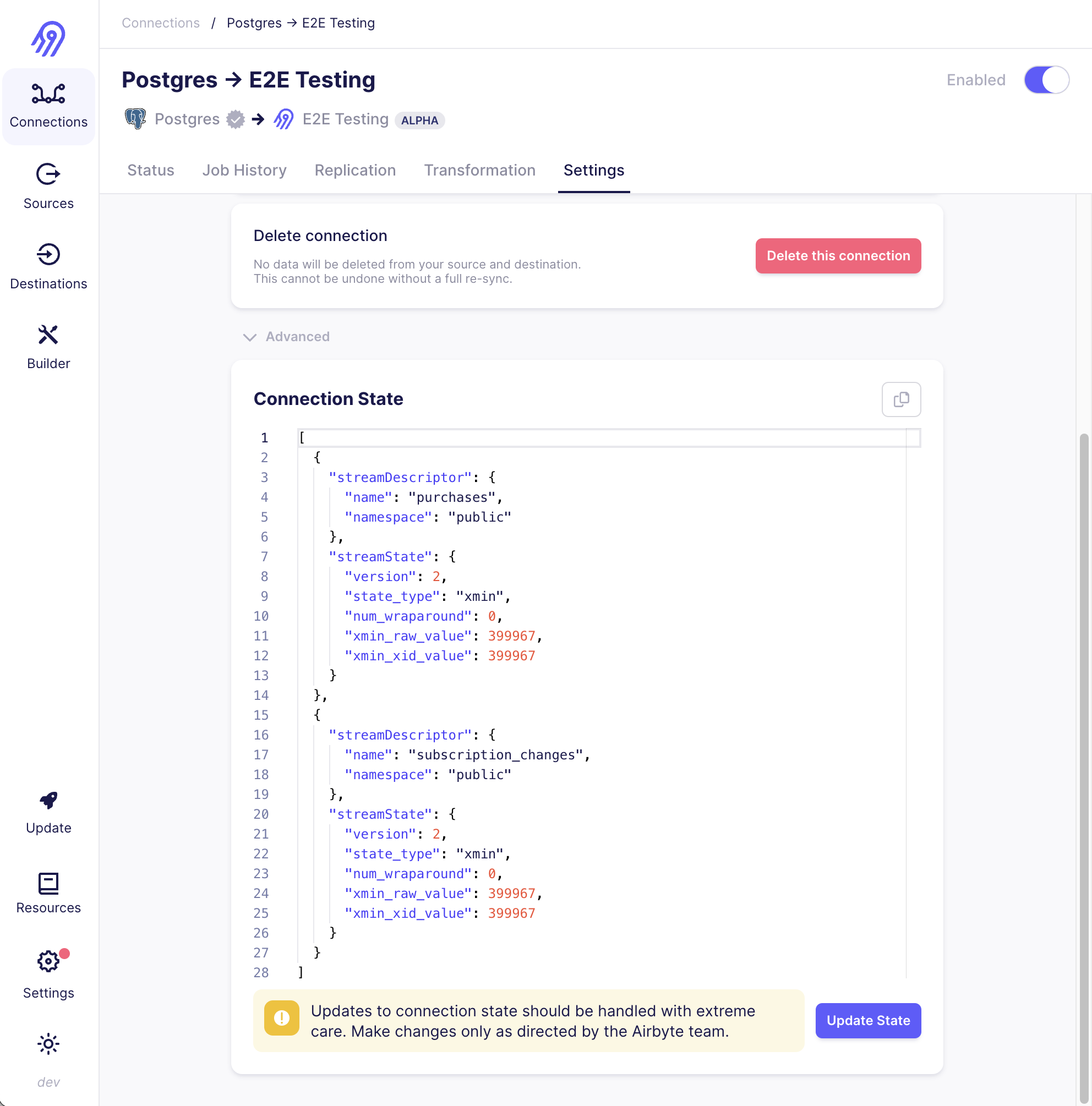
- Go to your newly created connection, replace the state with the copied contents in the previous step, then click
Update State. This will ensure historical data is not replicated again. - Enabling the connection will now provide a parallel copy of all streams in the updated format.
- You can move your dashboards to rely on the new tables, then pause the out-of-date connection.
Testing Destinations V2 for a Single Connection
You may want to verify the format of updated data for a single connection. To do this:
- If all of the streams you are looking to test with are in full refresh mode, follow the steps for upgrading connections one by one. Ensure any connections you create have a
Manualreplication frequency. - For any streams in incremental sync modes, follow the steps for upgrading incremental syncs. For testing, you do not need to copy pre-existing raw data. By solely inheriting state from a pre-existing connection, enabling a sync will provide a sample of the most recent data in the updated format for testing.
When you are done testing, you can disable or delete this testing connection, and upgrade your pre-existing connections in place or upgrade one-by-one with dual writing.
Upgrading as a User of Raw Tables
If you have written downstream transformations directly from the output of raw tables, or use the "Raw JSON" normalization setting, you should know that:
- Multiple column names are being updated (from
airbyte_ab_idtoairbyte_raw_id, andairbyte_emitted_attoairbyte_extracted_at). - The location of raw tables will from now on default to an
airbyte_internalschema in your destination. - When you upgrade to a Destinations V2 compatible version of your destination, we will leave a copy of your existing raw tables as they are, and new syncs will work from a new copy we make in the new
airbyte_internalschema. Although existing downstream dashboards will go stale, they will not be broken. - You can dual write by following the steps above and copying your raw data to the schema of your newly created connection.
We may make further changes to raw tables in the future, as these tables are intended to be a staging ground for Airbyte to optimize the performance of your syncs. We cannot guarantee the same level of stability as for final tables in your destination schema, nor will features like error handling be implemented in the raw tables.
As a user previously not running Normalization, Upgrading to Destinations V2 will increase the compute costs in your destination data warehouse. This is because Destinations V2 will now be performing the operations to generate a final typed table. Some destinations may provide an option to disable this - check your connectors's settings.
Upgrade Paths for Connections using CDC
For each CDC-supported source connector, we recommend the following:
| CDC Source | Recommendation | Notes |
|---|---|---|
| Postgres | Upgrade connection in place | You can optionally dual write, but this requires resyncing historical data from the source. You must create a new Postgres source with a different replication slot than your existing source to preserve the integrity of your existing connection. |
| MySQL | All above upgrade paths supported | You can upgrade the connection in place, or dual write. When dual writing, Airbyte can leverage the state of an existing, active connection to ensure historical data is not re-replicated from MySQL. |
Destinations V2 Compatible Versions
For each destination connector, Destinations V2 is effective as of the following versions:
| Destination Connector | Safe Rollback Version | Destinations V2 Compatible | Upgrade Deadline |
|---|---|---|---|
| BigQuery | 1.10.2 | 2.0.6+ | November 7, 2023 |
| Snowflake | 2.1.7 | 3.1.0+ | November 7, 2023 |
| Redshift | 0.8.0 | 2.0.0+ | March 15, 2024 |
| Postgres | 0.6.3 | 2.0.0+ | May 31, 2024 |
| MySQL | 0.2.0 | [coming soon] 2.0.0+ | [coming soon] early 2024 |
Note that legacy normalization will be deprecated for ClickHouse, DuckDB, MSSQL, TiDB, and Oracle DB in early 2024. If you wish to add Destinations V2 capability to these destinations, please reference our implementation guide (coming soon).
[Open Source Only] Rolling Back to Legacy Normalization
If you upgrade to Destinations V2 and start encountering issues, as an Open Source user you can optionally roll back. If you are running an outdated Airbyte Platform version (prior to v0.50.24), this may occur more frequently by accidentally upgrading to Destinations V2. However:
- Rolling back will require resetting each of your upgraded connections.
- If you are hoping to receive support from the Airbyte team, you will need to re-upgrade to Destinations V2 by the upgrade deadline.
To roll back, follow these steps:
- In the Airbyte UI, go to the 'Settings page, then to 'Destinations'.
- Manually type in the previous destination version you were running, or one of the versions listed in the table above.
- Enter this older version to roll back to the previous connector version.
- Reset all connections which synced at least once to a previously upgraded destination. To be safe, you may reset all connections sending data to a previously upgraded destination.
If you are an Airbyte Cloud customer, and encounter errors while upgrading from a V1 to a V2 destination, please reach out to support. We do not always recommend doing a full reset, depending on the type of error.
Destinations V2 Implementation Differences
In addition to the changes which apply for all destinations described above, there are some per-destination fixes and updates included in Destinations V2:
BigQuery
Object and array properties are properly stored as JSON columns
Previously, we had used TEXT, which made querying sub-properties more difficult. In certain cases, numbers within sub-properties with long decimal values will need to be converted to float representations due to a quirk of Bigquery. Learn more here.
Snowflake
Explicitly uppercase column names in Final Tables
Snowflake will implicitly uppercase column names if they are not quoted. Airbyte needs to quote the column names because a variety of sources have column/field names which contain special characters that require quoting in Snowflake. However, when you quote a column name in Snowflake, it also preserves lowercase naming. During the Snowflake V2 beta, most customers found this behavior unexpected and expected column selection to be case-insensitive for columns without special characters. As a result of this feedback, we decided to explicitly uppercase column names in the final tables, which does mean that columns which previous required quoting, now also require you to convert to the upper case version.
For example:
-- Snowflake will implicitly uppercase column names which are not quoted
-- These three queries are equivalent
SELECT my_column from my_table;
SELECT MY_COLUMN from MY_TABLE;
SELECT "MY_COLUMN" from MY_TABLE;
-- However, this query is different, and requires a lowercase column name
SELECT "my_column" from my_table;
-- Because we are explicitly upper-casing column names, column names containing special characters (like a space)
-- should now also be uppercase
-- Before v2
SELECT "my column" from my_table;
-- After v2
SELECT "MY COLUMN" from my_table;
Postgres
Preserving mixed case column names in Final Tables
Postgres will implicitly lower case column names with mixed case characters when using unquoted identifiers. Based on feedback, we chose to replace any special characters like spaces with underscores and use quoted identifiers to preserve mixed case column names.
Updating Downstream Transformations
This section is targeted towards analysts updating downstream models after you've successfully upgraded to Destinations V2.
See here for a breakdown of changes. Your models will often require updates for the following changes:
Column Name Changes
_airbyte_emitted_at_and_airbyte_extracted_atare exactly the same, only the column name changed. You can replace all instances of_airbyte_emitted_atwith_airbyte_extracted_at._airbyte_ab_idand_airbyte_raw_idare exactly the same, only the column name changed. You can replace all instances of_airbyte_ab_idwith_airbyte_raw_id.- Since
_airbyte_normalized_atis no longer in the final table. We now recommend using_airbyte_extracted_atinstead.
Data Type Changes
You'll get data type errors in downstream models where previously string columns are now JSON. In BigQuery, nested JSON values originating from API sources were previously delivered in type string. These are now delivered in type JSON.
Example: In dbt, you may now get errors with functions such as regexp_replace. You can attempt prepending these with json_extract_array(...) or to_json_string(...) where appropriate.
Stale Tables
Unnested tables (e.g. public.users_address) do not get deleted during the migration, and are no longer updated. Your downstream models will not throw errors until you drop these tables. Until then, dashboards reliant on these tables will be stale.